Research Areas in HPCL
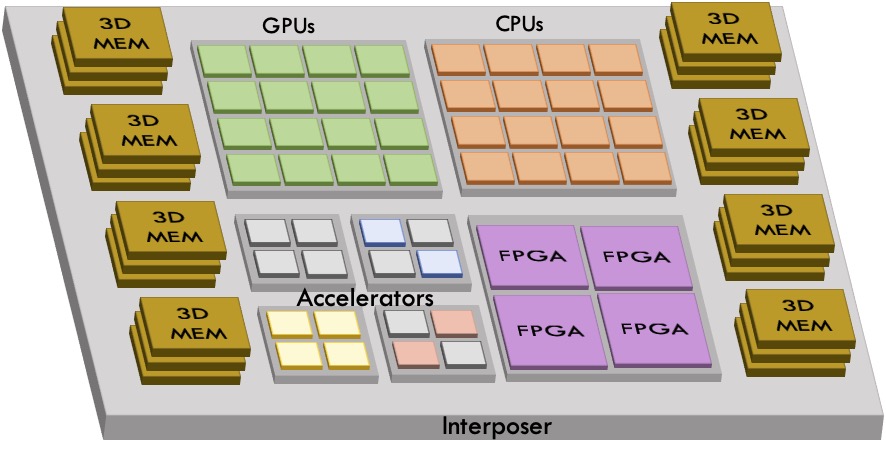
Communication Architecture Designs for Future Heterogeneous Systems
(NSF project, 2021-present)
|
Communication Algorithm and Hardware Co-Design for Distributed Deep Learning: The onset of the
big data era and rapid advances of accelerator architectures have enabled deep learning applications to
achieve superhuman accuracy on complex real-world problems, such as image recognition, natural
language processing, and autonomous driving. State-of-the-art DNN models such as GPT-3 have hundreds
of billions of parameters, requiring trillions of compute operations and hundreds of gigabytes of storage and
massive bandwidth. As data keep exploding and DNNs evolve to be larger and deeper, grids of specialized
accelerators have been designed and deployed to train DNN models in a parallel and distributed manner.
Large-scale distributed deep learning training has enabled developments of more complex deep neural
network models to learn from larger datasets for sophisticated tasks. In particular, distributed stochastic
gradient descent intensively invokes all-reduce operations for gradient update, which dominates
communication time during iterative training epochs.
In this work, we identify the inefficiency in widely used all-reduce algorithms, and the opportunity of
algorithm-architecture co-design. We propose MULTITREE all-reduce algorithm with topology and resource
utilization awareness for efficient and scalable all-reduce operations, which is applicable to different
interconnect topologies. Moreover, we co-design the network interface to schedule and coordinate the all-reduce messages for contention-free communications, working in synergy with the algorithm. The flow
control is also simplified to exploit the bulk data transfer of big gradient exchange. We evaluate the co-design using different all-reduce data sizes for synthetic study, demonstrating its effectiveness on various
interconnection network topologies, in addition to state-of-the-art deep neural networks for real workload
experiments.
|
|
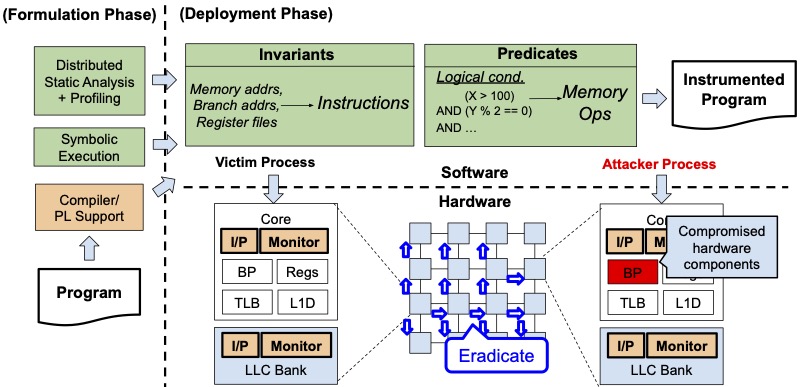
Hardware Security Provision in Multicore Architecture (2019-present)
|
Security has been identified as one of the grand challenges of the 21st century.
Security vulnerabilities can cause billion-dollar worth of damage, as exemplified in the recent fiasco of Wells Fargo and eleven other financial institutions.
Hardware security, in particular, has become the new territory of exploitation, including the recently-discovered Spectre and Meltdown vulnerabilities.
This project aims to tackle a new threat model where the hardware is not trusted as entirety.
Either one part of the CPU can be vulnerable and be controlled by the attacker, as exemplified by Spectre attacks, or a compromised or confused CPU can attack other CPUs in a multicore or multi-socket setting.
These intra-CPU and inter-CPU threat models in multicore systems will be increasingly crucial, being different from the traditional software-centered, intra- and inter-context (process) models.
We need new security principles at the hardware design stage to fortify the internal defense of the hardware,
by placing security checking at intra- and inter-CPU components and enforcing security isolation on inter-CPU communication in multicore architecture.
We have developed a well-integrated and cross-layer framework to embed security checking and isolation into architectural design.
With the framework, we explore new security policies and defense mechanisms to mitigate threat vectors inside CPU architecture and across CPU network in multicore architecture.
|
|
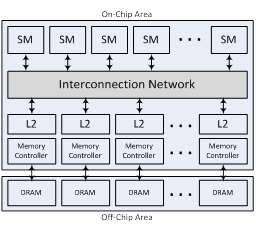
High
Performance On-Chip Interconnects Design for Multicore Accelerators (NSF project, 2014 - 2018)
|
Multicore
Accelerators like GPUs have recently obtained attention as a
cost-effective approach for data parallel architectures, and the fast
scaling of the GPUs increases the importance of designing an ideal
on-chip interconnection network, which impacts the overall system
performance. Since shared buses and crossbar can provide networking
performance enough only for a small number of communication nodes,
switch-based networks-on-chip (NoCs) have
been adopted as an emerging design trend in many-core environments.
However, NoC for Multicore Accelerator architectures has not been
extensively explored. While the major communication of Chip
Multiprocessor (CMP) systems is core-to-core for shared caches, major
traffic of Multicore Accelerators is core-to-memory, which makes the
memory controllers hot spots. Also, since Multicore Accelerators
execute many threads in order to hide memory latency, it is critical
for the underlying NoC to provide high bandwidth.
In
this project, we develop a framework for high-performance,
energy-efficient on-chip network mechanisms in synergy with Multicore
Accelerator architectures. The desirable properties of a target
on-chip network include re-usability across a wide range of Multicore
Accelerator architectures, maximization of the use of routing
resources, and support for reliable and energy-efficient data
transfer.
|
|
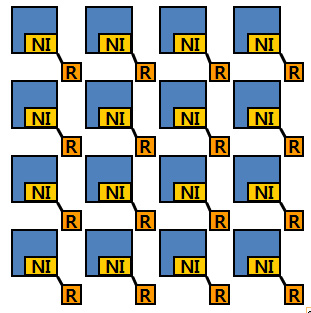
Communication-Centric Chip
Multiprocessor Design
(NSF CAREER, 2009 - 2014)
|
Chip
Multiprocessor Systems (CMPs) have embarked a paradigm shift from
computation-centric to communication-centric system design, as the
number of cores in a chip increases. To overcome traditional
interconnects problems, Network-on-Chip (NoC), using switch-based
networks, has been widely accepted as a promising architecture to
orchestrate chip-wide communication. Although interconnection network
design has matured in the context of multiprocessor architectures,
NoC has different characteristics for chip-wide communication
support, making its design unique. For example, NoC can benefit from
high wire densities and abundant metal layers. However, the cost of
NoC is constrained in terms of power and area. The design of
high-performance, low-power, and area-efficient NoC can be extremely
challenging, because these different objectives conflict with each
other in many cases. We are exploring innovative ideas on NOC design
considering a multi-dimensional design space and technology
constraints.
|
|
.
Dynamic Thermal Management in
CMPs
As
the significant heat is converted by the ever-increasing power density
and current leakage, the raised operating temperature in a chip have
already threatened the system reliability and led the thermal control
to be one of the most important issues needed to be addressed
immediately in the chip design. Due to the cost and complexity of
designing thermal packaging, many Dynamic Thermal Management (DTM)
schemes have been wildly adopted in the modern processors as a
technique to control CPU power dissipation. However, it is known that
the overall temperature of a CMPs is highly
correlated with temperature of each core in the CMPs environments;
hence, the thermal model for uniprocessor environments cannot be
directly applied in CMPs due to the potential heterogeneity. To our
best knowledge, none of prior DTM schemes considers the thermal
correlation effect among neighboring cores, neither the dynamic
workload behaviors which present different thermal behaviors. We
believe that it is necessary to develop an efficient online workload
estimation scheme for DTM to be applicable to the real world
applications which have variable workload behaviors and different
thermal contributions to the increased chip temperature.
|
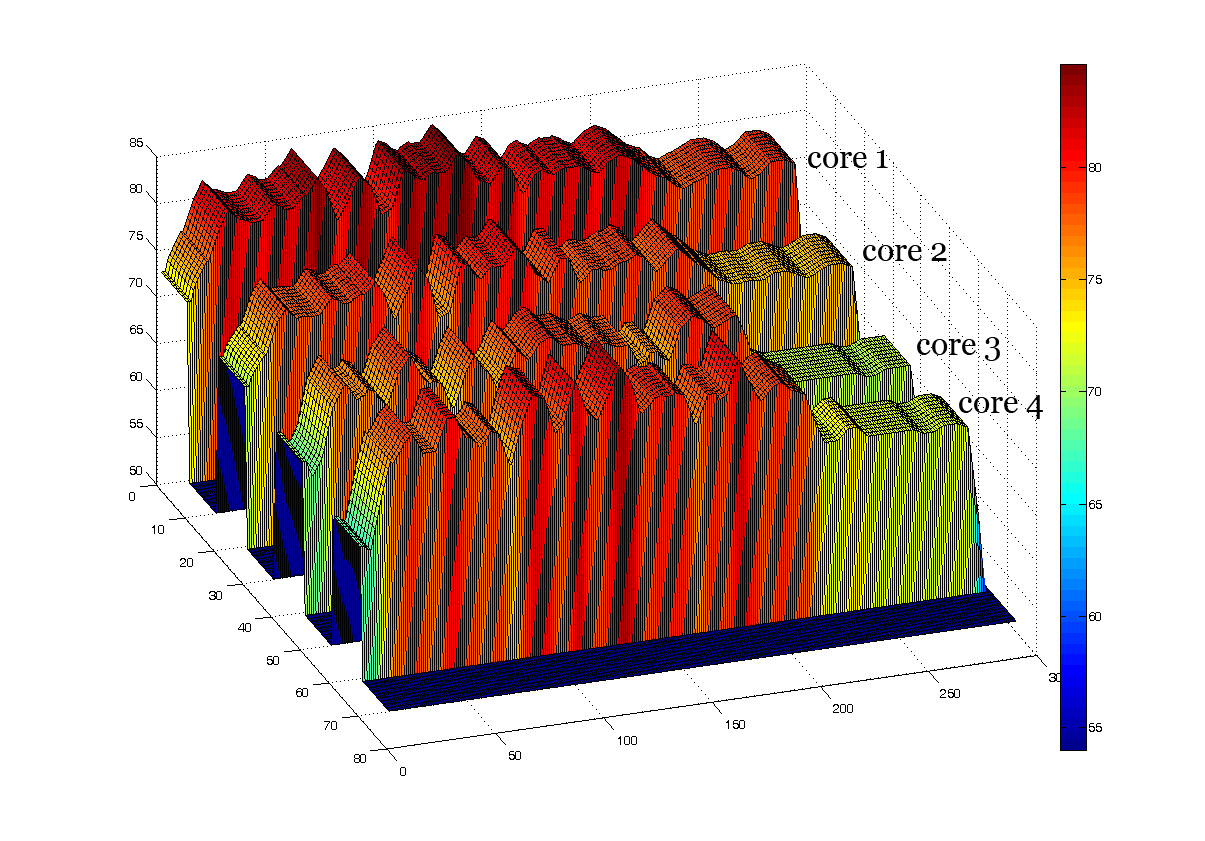
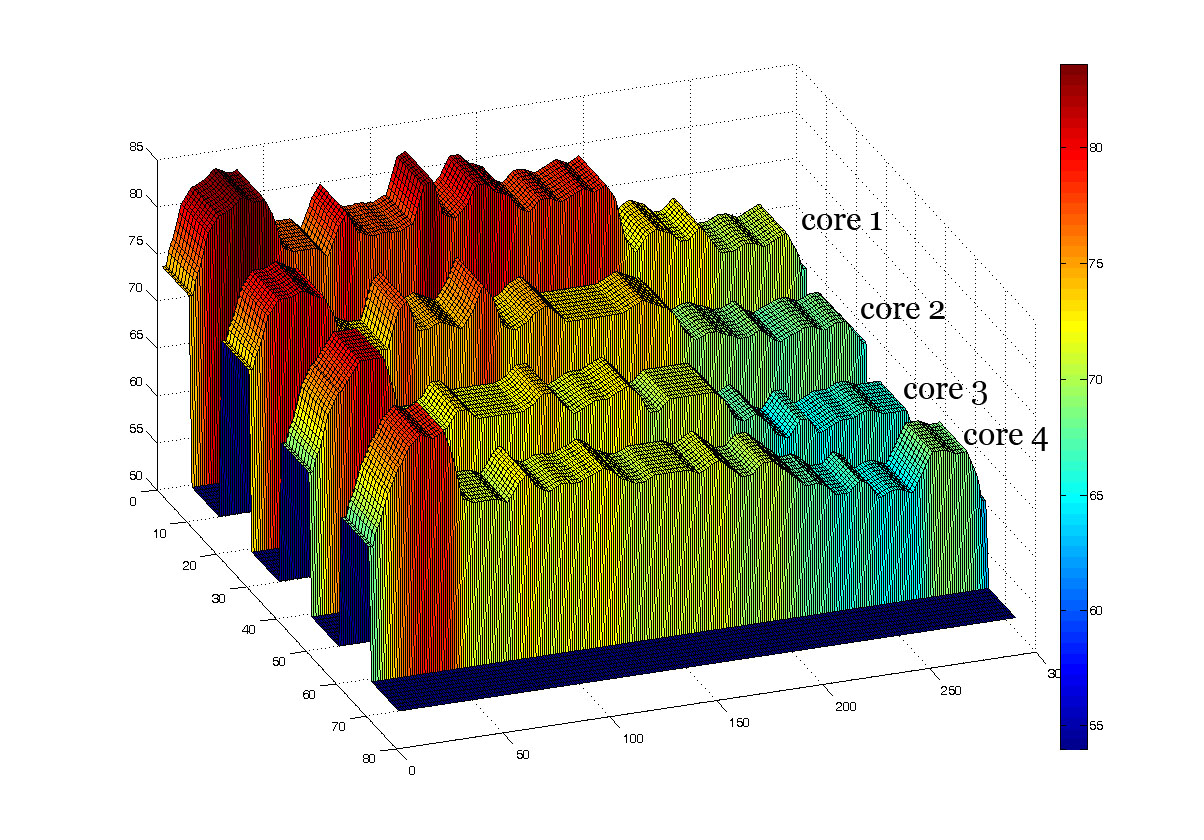
Comparisons between without
DTM and PDTM
|
|
|
|
|
Without DTM
|
PDTM
|
High Performance,
Energy Efficient and Secure Cluster design (NSF project, 2006 - 2009)
Clusters
have been widely accepted as the most effective solution to design high
performance servers, which are increasingly being deployed in
supporting a wide variety of Web-based services. Along with high and
predictable performance, optimization of energy consumption in these
servers has become a serious concern due to their high power budgets.
In addition, the critical nature of many Internet-based services
mandates that these systems should be robust to attacks from the
Internet, since numerous security loopholes of cluster servers have
been revealed. Although some initial investigation on cluster energy
consumption and security has appeared recently, an in-depth design and
analysis of a cluster interconnect considering the three parameters
mentioned above have not been undertaken.
|
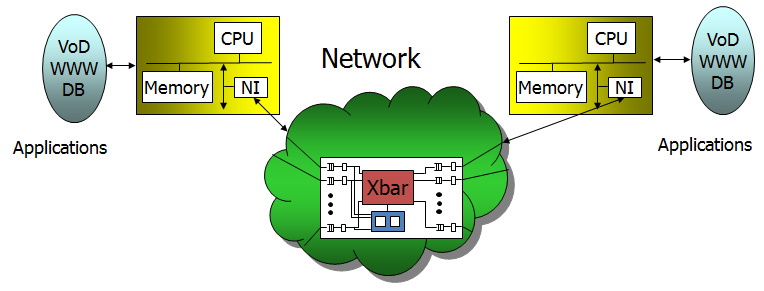
Cluser Interconnect Design
|
|
|
· High
Performance and Energy Efficient Cluster Interconnect Design
· Secure Cluster
System
·
High
Performance Web Cluster
Embedded Software Solutions in
Wireless Environments
(ETRI project, 2005 - 2008)
In
this project, we attempt to provide software solutions for these two
applications; multimedia streaming services in wireless LAN
environments and fault-tolerant wireless sensor network design. Video
streaming is currently gaining more interest from end-users as their
access speed to network is steadily increasing. Due to the increasing
popularity of hand-held devices and wireless laptops, the final access
points are mostly in wireless environments. For energy efficiency in
wireless sensor networks, dynamic reconfiguration, where only a subset
of sensor nodes is active with some interval, has been widely adopted.
However, maintaining required K-coverage and connectivity is critical
for the dynamic reconfiguration of wireless sensor networks.
|